
🐸 9월 23일 20일차
9월 23에는 정글 크래프톤에 퀴즈를 위해 알고리즘 개념 위주로 공부를 하였다.
2주차 공부 키워드
- 그래프 종류 / 표현방식
- BFS / DFS
- 위상 정렬
- B- Tree
- 트라이 (Trie)
- 다익스트라, 플로이드 와샬
- 최소 신장 트리
BFS와 DFS 같은 경우 계속 알고리즘 문제를 풀어왔기 때문에 개념에 알아보지 않았다.
주로 다익스트라 알고리즘에 대해 예시를 풀어보고 백준 관련 문제를 풀었다.
그리고 위상정렬, 플로이드 와샬, MST(최소신장트리) 같은 경우 개념만 이해하고 손으로 문제를 풀어보았다.
🔗다익스트라 알고리즘


다익스트라는 한 정점에서 다른 정점까지 최단 경로를 찾는 것이다.
주로 도로 교통망 같은 곳에서 사용되고, 주로 양의 간선 값을 가진다.
기본 알고리즘을 사용하면 시간복잡도가 O(V^2)이 되고,
우선순위 큐를 사용하면 시간복잡도 같은 경우 O(ElogE) 가 된다.
🔗 위상 정렬

비순환 방향 그래프로 모든 간선이 오른쪽만을 가르킨다.
이 경우 진입 차수가 0인 것을 찾고 연결된 노드를 스택에 넣어서 순서를 정렬해면된다.
🔗 플로이드 워셜
플로이드 워셜 또는 플로이드 와셜은 모든 지점에서 다른 모든 지점까지의 최단 경로이다.
다익스트라는 한점에서 다른 모든 노드의 최단 거린인데, 플로이드 워셜은 전부를 찾는 것이다.
플로이드 워셜은 여러 라운드로 구성되어있고, 2차원 인접 행렬을 구성한다.
라운드마다 각 경로에 새로운 중간 노드로 사용할 수 있는 노드를 선택하고,
더 짧은 길이를 선택하여 줄여준다.
확실히 모든 노드들의 각각의 최단거리를 구해야해서,
구하는데 시간이 좀 걸렸다.
해당 알고리즘의 시간 복잡도는 O(N^3)이다.

🔗유니온 파인드

크루스칼과 프림 알고리즘을 알기 위해서는 유니온 파인드 알고리즘을 알아야한다.
여러 노드가 존재할 때 어떤 두개의 노드를 같은 집합으로 묶어주고,
어던 두 노드가 같은 집합에 있는지 확인하는 알고리즘이다.
그야말로 Union 연산과 Find 연산...
🔗MST (최소신장트리) / Minimum Spanning Tree

[Spanning Tree]
그래프 내에 모든 정점을 포함하는 트리이다.
N개의 정점을 사이클 없이 N-1개의 간선으로 연결한다.
(먼저 스패닝 트리에 대해 알아야 한다. )
크루스칼 알고리즘과 프림 알고리즘 자체는 비슷하다.
단지 간선이 주어졌을때 어떻게 처리하느냐에 따라 다르다.
- Kruskal (크루스칼) 알고리즘
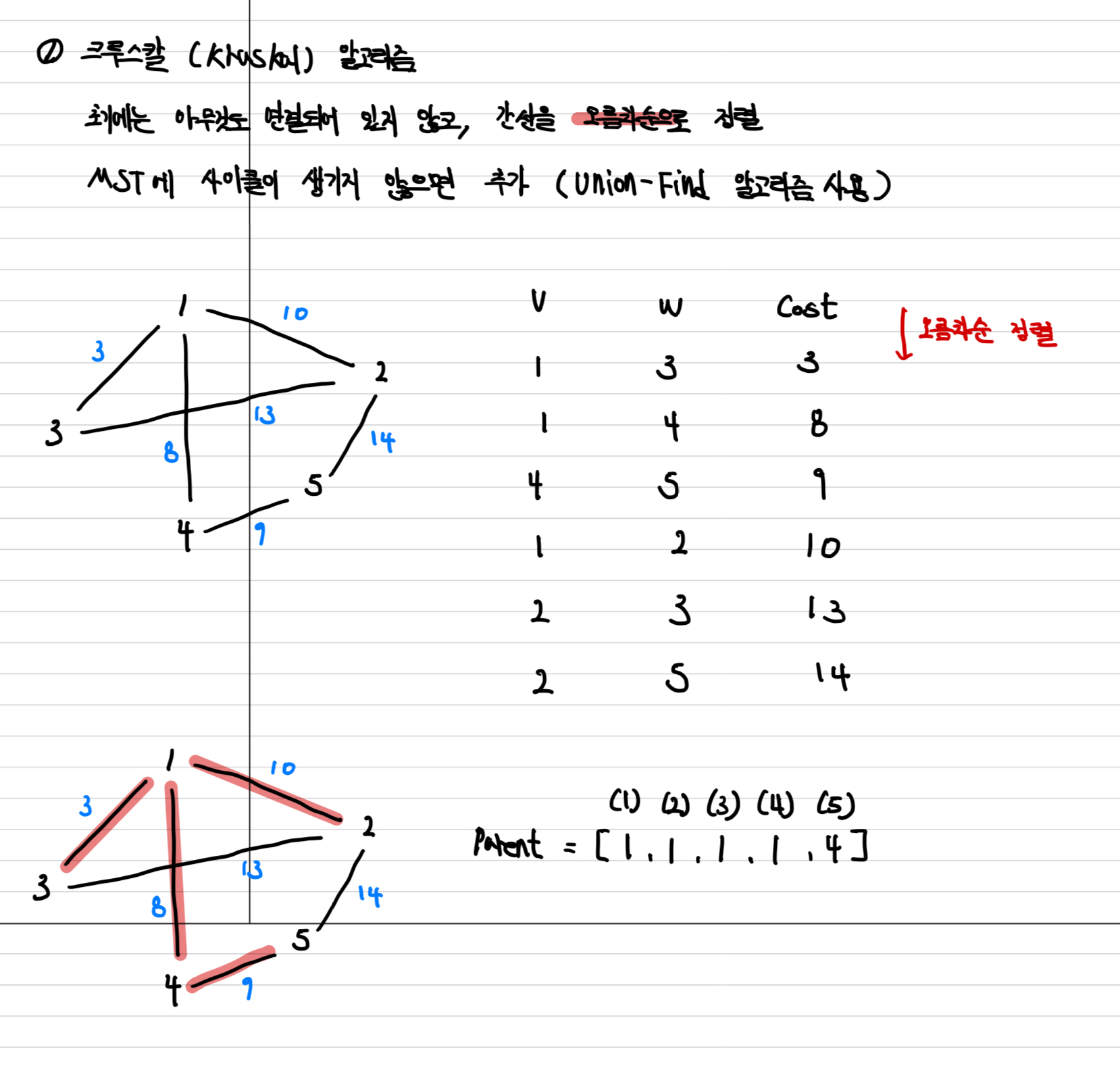
크루스칼 알고리즘 같은 경우 초기에 아무것도 연결되지 않고,
간선을 오름차순으로 정렬하고 사이클이 생기지 않게 간선을 추가한다.
(Union Find로 확인)
처음부터 모든 간선을 정렬 후 처음 시작한 노드를 선택한다.
시간 복잡도는 O(ElogV) 가 된다.
(V는 정점의 수, E는 간선의 수)
- Prim (프림) 알고리즘

프림 알고리즘도 역시 초기에는 아무것도 연결하지 않고 간선을 하나씩 추가하여 만든다.
시작 정점을 정해서 우선 순위 큐에 넣고 우선 순위 큐가 빌때까지 반복한다.
해당 알고리즘에서 시간 복잡도는 O(ElogV)가 된다.
각각의 알고리즘에 대해 다시 상기시킬 수 있어서 좋았다.
하지만 해당 알고리즘을 코드로 구현하는 것은 어렵다 ...
다익스트라 같은 경우 문제를 풀어 코드 구현을 연습해보았다.
[Python][백준] 11725. 트리의 부모 찾기 / 우선순위 큐, 다익스트라(G4)
🔗링크 : https://www.acmicpc.net/problem/1753🗒️파이썬 코드 풀이import sysimport heapqinput = sys.stdin.readlineV,E = map(int,input().split())K = int(input())linked_lst = [[] for _ in range((V+1))]for _ in range(E): u,v,w = map(int,input(
jerry-k.site
🐸 9월 24일 21일차
이날 주요 키워드는 정글 크래프톤의 2주차 쪽지 시험이다.
우선 오전에는 간단하게 나올 알고리즘 개념들에 대해 흩어보았다.
점심을 먹고 이후 쪽지시험을 보았다.
쪽지시험 위주로 TIL을 진행해본다.
Q. 캐시 메모리를 사용하면 컴퓨터 시스템의 성능이 왜 향상되는지 지역성 개념을 포함하여 설명하시오.
[나의 대답]
캐시 메모리는 일반적으로 프로세서와 메모리간의 격차를 줄이는 것을 목표로 존재한다.
자주 사용되는 데이터 또는 사용할 것 같은 데이터를 캐시에 저장한다.
이때 지역성이라는 개념을 활용한다. 지역성에는 공간 지역성, 시간 지역성이 있는데
공간 지역성 같은 경우 사용되고 있는 데이터의 주소 근처의 데이터를 가져오고,
시간 지역성 같은 경우 최근에 사용한 데이터를 캐시에 저장한다.
여기에서 실제 사용되는 데이터가 잘 예측 된 경우 캐시 히트가 높게 나온다.
[퀴즈 답안]
지역성은 프로그램이 메모리를 접근할 때 특정 부분을 집중적으로 사용하는 경향을 나타낸다.
- 시간적 지역성 : 한 번 접근된 데이터는 가까운 미래에 다시 접근될 가능성이 높다는 원리다.
ex) 루프 내에서 반복적으로 사용되는 변수
- 공간적 지역성 : 메모리의 특정 주소에 접근한 후, 그 주변 주소에 있는 데이터에 접근 될 가능성이 높다는 원리
ex) 배열이나 연속적인 메모리 블록에 접근할 때 종종 발생
캐시 메모리는 이러한 지역성 원리를 활용하여 자주 사용되거나 연속적으로 사용될 가능성이 높은 데이터를 미리 캐시에 저장한다. 이로 인해 CPU는 필요한 데이터를 캐시에서 빠르게 찾을 수 있다.
→ 대체적으로 나쁘게 쓰지는 않은 것 같다. 다만 핵심 내용만 쓰면 되는데 굳이 캐시 히트까지 쓸 이유가 있었을까? 한다.
괜히 너무 아는척하지말고 딱 문제에 요구하는 것만 풀자.
Q. DFS와 BFS를 pseudo 코드로 구현해보세요.
[나의 대답]
[BFS]
Queue 자료구조 (시작 점을 삽입)
while Queue (큐가 빌 때 까지)
v = Queue.popleft()
if 조건문 → Queue.append()
[DFS]
def dfs()
if 탈출 조건 (재귀 탈출 ) - return
dfs() → 재귀함수 호출
→ DFS는 스택구조로 재귀를 타고 타고 끝까지 간다
[퀴즈 답안]
def dfs(graph,start_node):
visit = list()
stack = list()
stack.append(start_node)
while stack:
node = stack.pop()
if node not in visit:
visit.append(node)
stack.extend(graph[node])
return visit
def bfs(graph,start_node):
visit = list()
queue = list()
queue.append(start_node)
while queue:
node = queue.pop(0)
if node not in visit:
visit.append(node)
queue.extend(graph[node])
return visit
DFS가 스택 구조라는 것은 알았지만, 단순히 재귀를 의미하는 줄 알았다.
근데 이런식으로 쓸 수 있는게 신기했다.
→ 최대한 코드를 쓰지 않으려고 해서 그런지 나의 수도코드는 너무 ... 부족하다.
Q. 프로세스와 쓰레드의 차이를 설명하세요.
[나의 대답]
프로세스는 프로그램의 실행이라 보면 된다. 주로 운영체제에 의해 관리되고, PCB 상태로 가상 메모리에 저장되어 있다. 쓰레드는 프로세스 실행의 한 유닛(단위)이고 한 프로세스 내에 여러개의 쓰래드가 있을 수 있다. CPU의 작업 스케줄링에 쓰레드 단위로 스케줄링 한다.
- 프로세스는 실행 중인 프로그램
- 각 프로세스는 독립적인 메모리 공간을 가지고, PCB에 의해 상태가 추적된다.
→ "PCB 상태로 가상 메모리에 저장되어있다" 에서 PCB에 의해 프로세스가 추적되는 것이지, "PCB가 메모리에 저장되어 있다"는 아니다. 정확히 말해 PCB (Process Control Block)은 운영체제의 커널 영역에 저장된다.
(PCB에는 프로세스의 상태, 메모리 정보, CPU 레지스터 상태, 입출력 상태 등 중요한 정보 담김)
[퀴즈 답안]
프로세스 : 독립적으로 실행되는 프로그램의 인스턴스로, 자체적인 주소 공간, 메모리, 데이터 스택 및 다른 시스템 자원을 갖는다. 각 프로세스는 독립적인 메모리 공간과 시스템 자원을 가지므로, 프로세스간 자원 공유는 IPC 메커니즘을 통해 이뤄진다.
쓰레드 : 프로세스 내부의 실행 흐름 단위로 프로세스의 자원과 주소 공간을 공유하면서 실행된다. 같은 프로세스 내의 쓰레드들은 코드, 데이터 및 시스템 자원을 공유한다.
키워드가 시스템 자원 / 독립과 공유인데 , 이와 관련해서 쓰지 못했다.
좀 틀린 개념도 적었다 ... ^0^
Q. 다음과 같은 가중치가 할당된 그래프가 있을 때, 다익스트라 알고리즘을 사용하여 시작점 D에서 F 까지의 최단 경로를 찾고, 알고리즘 실행 중간과정 (상태)를 함꼐 기록하세요.
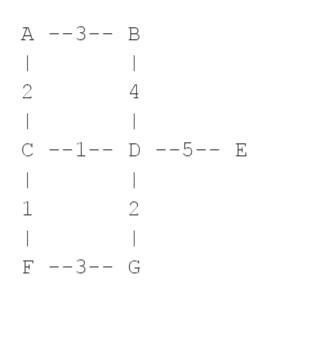
[나의 대답]

[퀴즈 답안]
1. 시작 노드 D 선택, D의 최단 거리 = 0
2. D의 모든 이웃 노드 확인
a) 인접 노드 C: D-C 거리 1로 C의 최단거리 = 1
...
3. 방문하지 않은 노드 중 최단 거리가 짧은 노드 C 선택
4. 선택된 노드 C의 모든 이웃 노드 확인
a) 인접 노드 최단 거리 갱신
5. 방문하지 않은 노드 중 최단 거리가 짧은 노드 F 선택
6. D - C -F 보다 짧은 거리는 없는 것으로 판명되어 종료
나는 최단 거리 갱신 과정들을 보여주었는데,
퀴즈 답안처럼 하는 방식처럼 저렇게 말로 서술하는 법도 연습해야겠다.
(저 방법을 생각하지 못함...)
Q. 데이터베이스에서 큰 양의 정렬된 데이터를 관리하고 있습니다. B-tree 인덱스를 사용하면 데이터 검색 성능이 향상될 수 있습니다. B-tree 인덱스를 사용할 때와 사용하지않을 떄의 데이터 검색 시간 복잡도를 Big O 표기법을 사용하여 비교하고 설명하세요.
[퀴즈 답안]
B-tree 인덱스를 사용할 때의 데이터 검색 시간 복잡도는 O(log n)이다. 여기서 n은 데이터베이스 내의 레코드 수이다. B-tree 구조는 균형 이진 트리와 유사하므로 데이터를 효율적으로 검색할 수 있다. 반면, B-tree 인덱스를 사용하지 않을 경우 선형 검색을 수행해야 하므로 검색 시간 복잡도는 O(n)이 된다. 따라서 데이터 양이 많을수록 B-tree 인덱스를 사용하는 것이 성능면에서 훨씬 유리하다.
이 문제는 풀지 못한 문제이로 사실 B 트리에대해 잘 이해도 못했다.
해당 문제로 B-tree 인덱스를 사용하면 시간 복잡도가 O(log n)이 되는 것을 잘 기억해두자.
데이터 양이 많을 경우 B-tree 인덱스를 사용하면 성능이 훨씬 좋아진다.
이게 끝나고 알고리즘 문제도 풀었지만, TIL 포스팅은 여기까지만... !
'크래프톤 정글' 카테고리의 다른 글
| 정글 7기 24, 25, 26일차 / DP, 휴식 (1) | 2024.10.02 |
|---|---|
| 정글 7기 22, 23일차 / 커피챗, 티타임, 크래프톤 채용 설명회 (3) | 2024.10.01 |
| 정글 7기 18, 19일차 / CS:APP(캐시, 운영 체제), 주말 회고 (1) | 2024.09.23 |
| 정글 7기 16,17일차 / CS:APP 스터디 준비 (0) | 2024.09.21 |
| 크래프톤 정글 7기 10, 11, 12 일차 + 추석 / 회고록, 알고리즘 팁, CTO 인터뷰 (7) | 2024.09.18 |